使用 Haproxy + Keepalived 构建基于 Docker 的高可用负载均衡服务(一)
适合具有 Docker 和 Bash 相关基础的开发、运维等同学。本文没有太过深入的介绍,也并没有用到一些高级特性,仅适合用来作为一个基础科普文来阅读。
背景
最近在搭新的 Coding 内部测试环境,老大说把以前使用 nginx 插件来做的 LB(Load balancing) 全部换成 HAProxy 来做。经过几天的不断“查阅资料”,简单实现了该服务的动态构建。
本文循序渐进按照以下几个层次来讲:
- HAProxy 与 Keepalived 的简单介绍
- HAProxy 介绍
-
Keepalived 介绍
-
搭建 haproxy + keepalived 服务过程
- 搭建业务服务
-
使用 HAProxy 做业务服务的高可用和负载均衡
-
使用 Keepalived 做 HAProxy 服务的高可用
环境准备:
- 五台 Linux 主机

- 一个虚拟的 IP
192.168.0.146(一个内网没人用的 IP)
HAProxy 与 Keepalived 简单介绍
HAProxy 是一个提供高可用、负载均衡和基于 HTTP/TCP 应用代理的解决方案。
Keepalived 是用 C 编写的路由软件,主要目标是为 Linux 系统及基于 Linux 的设施提供强大的高可用性和负载均衡。
在本文中,HAProxy 我们用来做 HTTP/TCP 应用的 HA + LB 方案,Keepalived 被用来做 HAProxy 的 HA 方案。下边是对两者的简单介绍和简单使用。
HAProxy
关于 HAProxy 的一些概念限于篇幅的原因不再详细说了,可以参考这篇文章: https://www.digitalocean.com/community/tutorials/an-introduction-to-haproxy-and-load-balancing-concepts
下边仅会介绍我们会使用到的一些概念。
HAProxy 的 Proxy 配置可以分为如下几个部分( http://cbonte.github.io/haproxy-dconv/1.7/configuration.html#4 ):
- defaults [
] - frontend
- backend
- listen
其中 defaults 包含一些全局的默认环境变量,frontend 定义了如何把数据 forward 到 backend,backend 描述了一组接收 forward 来的数据的后端服务。listen 则把 frontend 和 backend 组合到了一起,定义出了一个完整的 proxy。

下面是一段简单的 HAProxy 的配置:
listen app1-cluster
bind *:4000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:4004 maxconn 300 check
server server2 192.168.0.190:4004 maxconn 300 check
server server3 192.168.0.191:4004 maxconn 300 check
listen app2-cluster
bind *:5000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:5555 maxconn 300 check
server server2 192.168.0.190:5555 maxconn 300 check
server server3 192.168.0.191:5555 maxconn 300 check
我们在 HAProxy 的配置文件中定义了两个 listen 模块,分别监听在 4000、5000 端口。监听在 4000 端口的模块,使用 roundrobin (轮询)负载均衡算法,把请求分发到了三个后端服务。
Keepalived
关于 Keepalived 的详细介绍可以参考: http://keepalived.readthedocs.io/en/latest/introduction.html
Keepalived 是一个用于负载均衡和高可用的路由软件。
其负载均衡(Load balancing)的特性依赖于 Linux 虚拟服务器(LVS)的 IPVS 内核模块,提供了 Layer 4 负载均衡器(TCP 层级,Layer 7 是 HTTP 层级,即计算机网络中的OSI 七层网络模型与 TCP/IP 四层网络模型)。
Keepalived 实现了虚拟冗余路由协议(VRRP, Virtual Redundancy Routing Protoco),VRRP 是路由故障切换(failover)的基础。
简单来说,Keepalived 主要提供两种功能:
- 依赖 IPVS 实现服务器的健康检查;
- 实现 VRRPv2 协议来处理路由的故障切换。
我们接下来会用个简单的配置来描述后者的工作原理:
在 haproxy-master 机器上:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify haproxy's pid existance
interval 2 # check every 2 seconds
weight -2 # if check failed, priority will minus 2
}
vrrp_instance VI_1 {
state MASTER # Start-up default state
interface ens18 # Binding interface
virtual_router_id 51 # VRRP VRID(0-255), for distinguish vrrp's multicast
priority 105 # VRRP PRIO
virtual_ipaddress { # VIP, virtual ip
192.168.0.146
}
track_script { # Scripts state we monitor
chk_haproxy
}
}
在 haproxy-backup 机器上:
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight -2
}
vrrp_instance VI_1 {
state BACKUP
interface ens18
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.0.146
}
track_script {
chk_haproxy
}
}
我们为两台机器(master、backup)安装了 Keepalived 服务并设定了上述配置。
可以发现,我们绑定了一个虚拟 IP (VIP, virtual ip): 192.168.0.146,在 haproxy-master + haproxy-backup 上用 Keepalived 组成了一个集群。在集群初始化的时候,haproxy-master 机器的
间隔 2 seconds(
关于
- 检测失败,并且 weight 为正值:无操作
- 检测失败,并且 weight 为负值:priority = priority – abs(weight)
- 检测成功,并且 weight 为正值:priority = priority + weight
- 检测成功,并且 weight 为负值:无操作
weight 默认值为 0,对此如果感到迷惑可以参考:HAProxy github code
故障切换工作流程:
- 当前的 MASTER 节点 <script> 脚本检测失败后,如果“当前 MASTER 节点的 priority” < “当前 BACKUP 节点的 priority” 时,会发生路由故障切换。
- 当前的 MASTER 节点脚本检测成功,无论 priority 是大是小,不会做故障切换。
其中有几处地方需要注意:
- 一个 Keepalived 服务中可以有个 0 个或者多个 vrrp_instance
- 可以有多个绑定同一个 VIP 的 Keepalived 服务(一主多备),本小节中只是写了两个
- 注意
,同一组 VIP 绑定的多个 Keepalived 服务的 必须相同;多组 VIP 各自绑定的 Keepalived 服务一定与另外组不相同。否则前者会出现丢失节点,后者在初始化的时候会出错。
关于 Keepalived 各个参数代表含义的问题,可以同时参考下文与 Github 代码文档来看:
- keepalived工作原理和配置说明: http://outofmemory.cn/wiki/keepalived-configuration
-
Github keepalived.conf.SYNOPSIS: https://github.com/acassen/keepalived/blob/master/doc/keepalived.conf.SYNOPSIS
搭建 haproxy + keepalived 服务过程
搭建业务服务
我们在 host-1、host-2、host-3 三台机器上,每台机器的 4004、5555 端口分别启起来一个服务,服务打印一段字符串,用来模拟业务集群中的三个实例。
如下所示:
- 192.168.0.189/host-1
4004 端口:

5555 端口:

- 192.168.0.190/host-2
4004 端口:

5555 端口:

- 192.168.0.191/host-3
4004 端口:

5555 端口:

如上所示,我们在三台机器上搭建了两个集群,结构如下图所示:
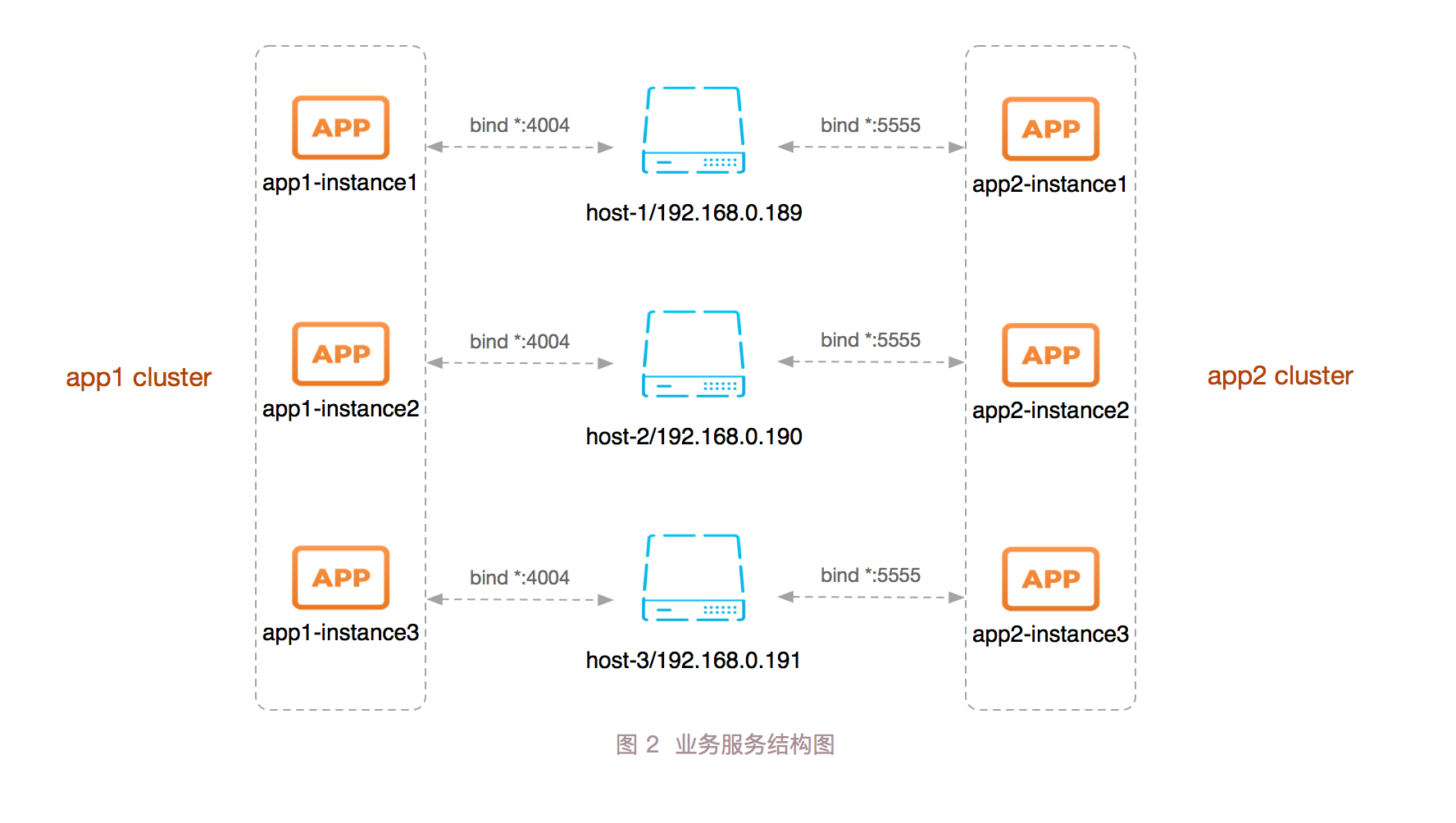
使用 HAProxy 做业务服务的高可用和负载均衡
我们现在有两台机器:haproxy-master、haproxy-backup,本小节的目标是在这两台机器上分别搭一套相同的 HAProxy 服务。(为了方便,下边直接用 Docker 做了)
我们直接使用了 haproxy:1.7.9 版本的 Docker 镜像,下边是具体的步骤:
coding@haproxy-master:~/haproxy$ tree .
.
├── Dockerfile
└── haproxy.cfg
0 directories, 2 files
coding@haproxy-master:~/haproxy$ cat Dockerfile
FROM haproxy:1.7.9
COPY haproxy.cfg /usr/local/etc/haproxy/
coding@haproxy-master:~/haproxy$ cat haproxy.cfg
global
daemon
maxconn 30000
log 127.0.0.1 local0 info
log 127.0.0.1 local1 warning
defaults
mode http
option http-keep-alive
option httplog
timeout connect 5000ms
timeout client 10000ms
timeout server 50000ms
timeout http-request 20000ms
# custom your own frontends && backends && listen conf
# CUSTOM
listen app1-cluster
bind *:4000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:4004 maxconn 300 check
server server2 192.168.0.190:4004 maxconn 300 check
server server3 192.168.0.191:4004 maxconn 300 check
listen app2-cluster
bind *:5000
mode http
maxconn 300
balance roundrobin
server server1 192.168.0.189:5555 maxconn 300 check
server server2 192.168.0.190:5555 maxconn 300 check
server server3 192.168.0.191:5555 maxconn 300 check
listen stats
bind *:1080
stats refresh 30s
stats uri /stats
在完成上述代码后,我们可以构建我们自己的 Docker 镜像,并运行它:
coding@haproxy-master:~/haproxy$ docker build -t custom-haproxy:1.7.9 .
Sending build context to Docker daemon 3.584kB
Step 1/2 : FROM haproxy:1.7.9
1.7.9: Pulling from library/haproxy
85b1f47fba49: Pull complete
3dee1a596b5f: Pull complete
259dba5307a2: Pull complete
9d51568f5880: Pull complete
d2c6077a1eb7: Pull complete
Digest: sha256:07579aed81dc9592a3b7697d0ea116dea7e3dec18e29f1630bc2c399f46ada8e
Status: Downloaded newer image for haproxy:1.7.9
---> 4bb854517f75
Step 2/2 : COPY haproxy.cfg /usr/local/etc/haproxy/
---> 4e846d42d719
Successfully built 4e846d42d719
Successfully tagged custom-haproxy:1.7.9
coding@haproxy-master:~/haproxy$ docker run -it --net=host --privileged --name haproxy-1 -d custom-haproxy:1.7.9
fb41ab81d2140af062708e5b84668b7127014eb9ae274e4c2761d06e2f6d7950
通过命令 docker ps -a 我们可以看到,容器已经正常运行了,接下来我们在 web 端打开相应的地址可以看到所有服务的状态:
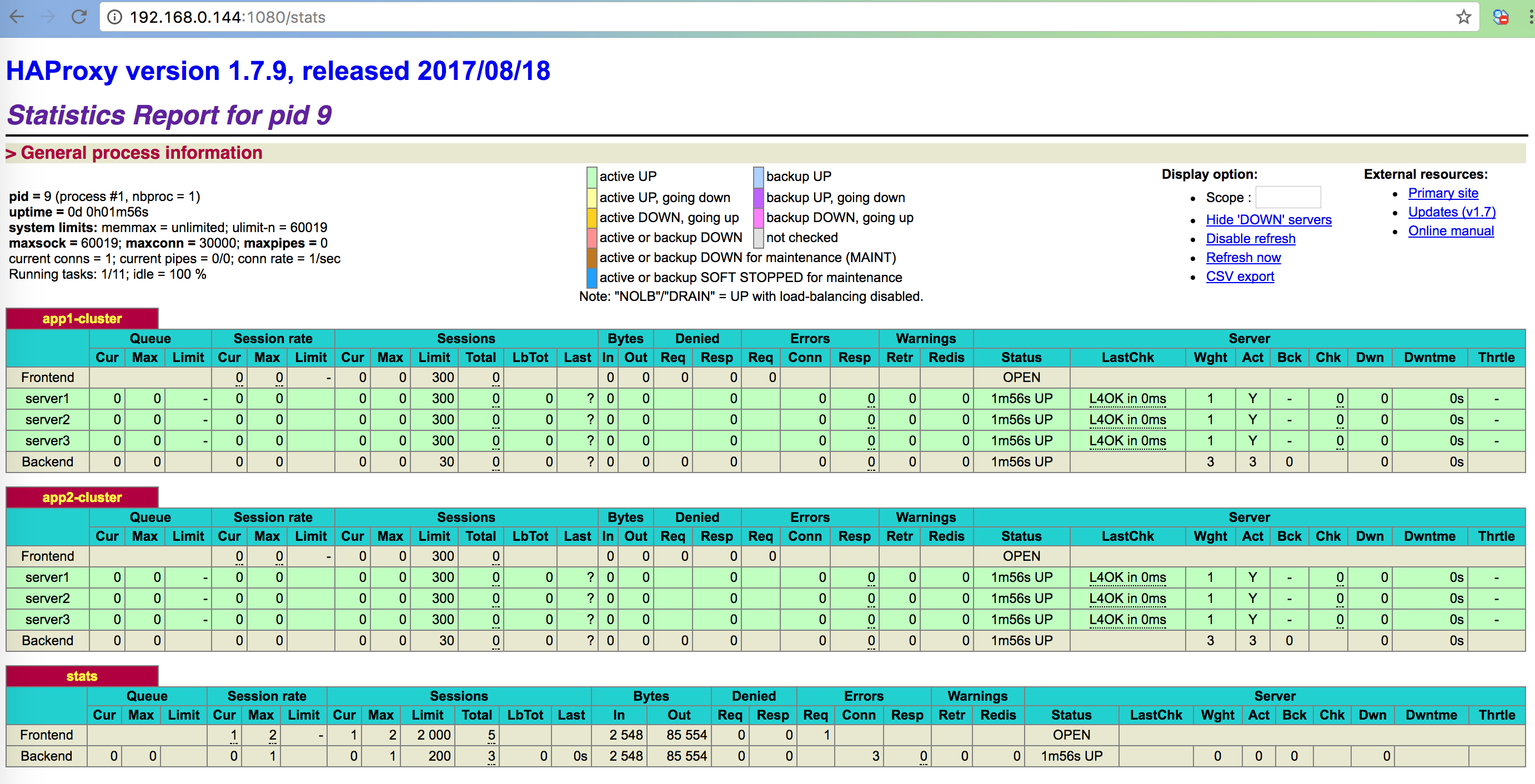
我们刚才在 haproxy-master 机器上搭建了一个 haproxy 服务,在其 4000、5000 端口绑定了两个业务集群。我们在浏览器访问:http://192.168.0.144:4000/、http://192.168.0.144:5000/ ,并且重复刷新即可看到会打印不同的 JSON 出来。可以证明我们请求确实是分发到了业务集群的几个实例中。
接下来,还要在 haproxy-backup 上搭建一个一模一样的 HAProxy 服务,步骤同上。
使用 Keepalived 做 HAProxy 服务的高可用
在上一小节中,我们在 haproxy-master、haproxy-backup 两台机器上搭了两套相同的 HAProxy 服务。我们希望在一个连续的时间段,只由一个节点为我们提供服务,并且在这个节点挂掉后另外一个节点能顶上。
本小节的目标是在haproxy-master、haproxy-backup 上分别搭 Keepalived 服务,并区分主、备节点,以及关停掉一台机器后保证 HAProxy 服务仍然正常运行。
使用如下命令安装 Keepalived:
coding@haproxy-master:~$ sudo apt-get install keepalived
coding@haproxy-master:~/haproxy$ keepalived -v
Keepalived v1.2.19 (03/13,2017)
我们在 haproxy-master 机器上,增加如下配置:
coding@haproxy-master:~$ cat /etc/keepalived/keepalived.conf
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
}
vrrp_instance VI_1 {
state MASTER
interface ens18
virtual_router_id 51
priority 105
virtual_ipaddress {
192.168.0.146
}
track_script {
chk_haproxy
}
}
在 haproxy-backup 机器上增加如下配置:
coding@haproxy-backup:~$ cat /etc/keepalived/keepalived.conf
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
}
vrrp_instance VI_1 {
state BACKUP
interface ens18
virtual_router_id 51
priority 100
virtual_ipaddress {
192.168.0.146
}
track_script {
chk_haproxy
}
}
在配置结束之后,我们分别重启两台机器上的 Keepalived 服务:
oot@haproxy-master:~# systemctl restart keepalived
(注:不同的发行版命令不同,本文基于 Ubuntu 16.04)
此时我们的 Keepalived 服务就搭建完成了,VIP 是 192.168.0.146。此时我们通过浏览器访问:http://192.168.0.146:1080/stats,即可看到 HAProxy 服务的状态。
我们也可以通过 ssh user@192.168.0.146 看目前 MASTER 节点为哪台机器。ssh 后发现目前的 MASTER 节点为 haproxy-master 机器,我现在把这台机器上的 haproxy 服务停掉:
root@haproxy-master:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
fb41ab81d214 custom-haproxy:1.7.9 "/docker-entrypoin..." About an hour ago Up 1 second haproxy-1
root@haproxy-master:~# docker stop fb41ab81d214
fb41ab81d214
然后我们访问:http://192.168.0.146:1080/stats,会在稍微停顿下后仍然能显示出来 haproxy 服务的状态。我们再 ssh user@192.168.0.146 后,发现我们进入了 haproxy-backup 机器上。此时的 MASTER 节点就是 haproxy-backup 机器。
以此来看,我们已经搭建出来了一个简单的 HAProxy + Keepalived 服务了。整体结构图如下所示:

结尾
有一点需要注意,容易混淆:
区分主节点、备节点是 Keepalived 服务来做的,HAProxy 在所有节点上的配置应该是相同的。
标签云
-
DeepinSSHVagrantLinuxSupervisorMongodbSecureCRTKubernetesMySQLOfficeGoogleAppleVPSSystemd备份DockerCDNFlutterShellGITOpenVZKloxoSwiftPostfixWordPressSocketAndroidOpenStacksquidOpenrestyNginxWindowsCurlCactiSwarmFirewalldIptablesSambaTcpdumpLUAMacOSLighttpdFlask监控TensorFlowJenkinsMariaDBKVMTomcat集群ZabbixPHPHAproxy部署iPhoneNFSCentosRsync容器YumDebianSaltStackCrontab缓存SQLAlchemyRedisPutty代理服务器ApacheIOSVirtualboxUbuntuMemcacheInnoDBKotlinWgetGolangPythonVirtualminWiresharkWPSAnsibleDNSSVNLVMRedhatSnmpBashVsftpdPostgreSQL